【Kerasリファレンス】全結合層(Dense)と活性化関数(Activation)

- 1. 初めに
- 2. Dense(全結合層)とは
- 3. 活性化関数とは
- 4. Dense(全結合ニューラルネットワーク)を用いるディープラーニングのモデル
- 5. kerasの活性化関数の指定方法
- 6. ディープラーニングの実装サンプル(keras)
- 7. Kerasリファレンス
- 8. 最後に
初めに

ディープラーニングの全結合層と活性化関数について説明するね。
Kerasのディープラーニングで利用できる全結合層(Dense)と活性化関数(Activation)について纏めました。
※ この記事はディープラーニングおよびKerasの知識がある方向けのリファレンスになります。
Dense(全結合層)とは
Denseレイヤーは、全結合層(全結合ニューラルネットワーク)の基本的な構成要素であり、各入力ニューロンが次のレイヤーのすべてのニューロンに接続されている、いわゆる全結合層(Fully Connected Layer)です。
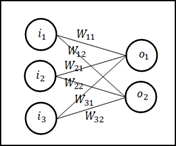
全結合層とは
全結合層(fully connected layer)は、ニューラルネットワークの層の一種で、各ニューロンが前の層のすべてのニューロンと接続されている層を指します。全結合層は、ニューラルネットワークの中で最も基本的かつ一般的な構成要素の一つです。
全結合層の基本概念
全結合層では、各ニューロンが前の層のすべてのニューロンから入力を受け取り、その結果を次の層に送ります。例えば、ある層のニューロン数が𝑁、次の層のニューロン数が𝑀であれば、全結合層では𝑁×𝑀個の重みが存在します。
全結合層の計算方法
全結合層は、前の層の出力に対して重み付けを行い、すべての重み付き入力の総和を計算します。その総和にバイアス項を加え、さらに活性化関数を適用して最終的な出力を計算します。数式で表すと以下のように計算されます。
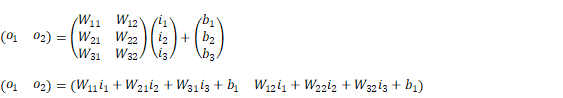
全結合層の表現力
全結合層は、非常に多くのパラメータ(重みとバイアス)を持つため、非常に表現力が高いです。このため、複雑な関数やパターンを学習する能力があります。ただし、多くのパラメータを持つため、計算量とメモリ消費が非常に大きくなることがあります。これが、特に大規模なモデルやデータセットを扱う際の課題となります。
活性化関数とは
活性化関数(activation function)は出力層の結果を求める答えににあった形式に変換する機能となります。入力信号の重み付き和に非線形性を導入することで、ニューラルネットワークが複雑なパターンや関数を学習する能力を向上させます。
計算式とグラフで見て頂いた方が分かり易いかと思いますので、以下に活性化関数のイメージを記載します。
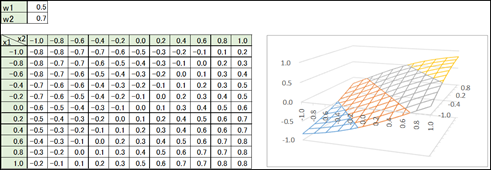
全結合の計算式は以下の様になります。
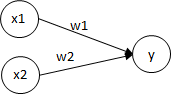
y = x1×w1 + x2×w2
これをグラフにすると御覧の通り、線形(Xに比例する直線)しか表現することが出来ません。
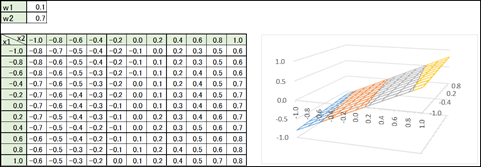
そのため、線形関数と非線形関数を組み合わせて複雑なパターンを表現します。
線形関数と非線形関数を組み合わせることであらゆるパターンの関数が出来ると言われています。
例)
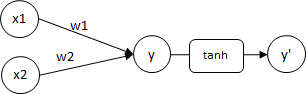
y = x1×w1 + x2×w2
y' = tanh(y)
これをグラフにすると御覧の通り、非線形の線を表現することが出来ます。
ディープラーニングは全結合(線形関数)と活性化関数(非線形関数)を組み合わせることで複雑なパターンを表現します。
【ディープラーニングのネットワーク構成のイメージ】

活性化関数は幾つか代表的なものがあり、状況に応じて使い分けます。以下に代表的な活性化関数を紹介します。
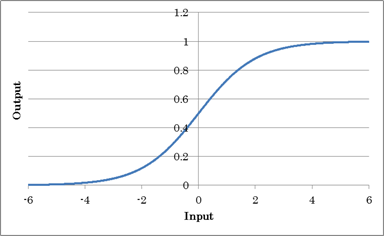
シグモイド関数(Sigmoid Function)
入力値のSigmoidによる処理結果を出力する活性化関数です。確率など0.0~1.0の出力値を得たい場合に使用します。
数式
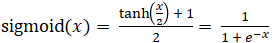
利用用途
Sigmoid関数はLSTM等の連続データの回帰分析を行うネットワークにおいて、出力層の結果を0~1の範囲に変換するために利用します。Sigmoid関数には勾配消失問題があるため中間層では使われません。中間層には勾配消失問題が少ないReLUなどの活性化関数を用いるのが一般的です。
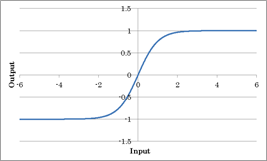
ハイパボリックタンジェント関数(Tanh Function)
入力値のTanhによる処理結果を出力する活性化関数です。
数式
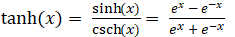
利用用途
Tanh関数はLSTM等の連続データの回帰分析を行うネットワークにおいて、出力層の結果を-1~1の範囲に変換するために利用します。Tanh関数には勾配消失問題があるため中間層では使われません。中間層には勾配消失問題が少ないReLUなどの活性化関数を用いるのが一般的です。
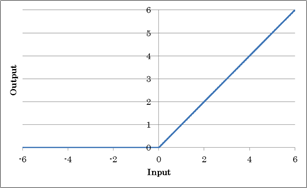
ReLU(Rectified Linear Unit)
入力値のReLU(Rectified Linear Unit)による処理結果を出力する活性化関数です。
中間層の活性化関数として使用します。2019年5月現在、中間層で用いる活性化関数として最も優れている関数の一つです。なお、ReLUは出力層で用いられることは殆どありません。
数式
y=max(0, x)
上記は0かxの大きい方をyとする意味です。
すなわち、xが0未満ならyは常に0、xが0以上であればy = x となります。
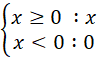
利用用途
ReLU関数は中間層の活性化関数として現在最も多く用いられる関数の一つです。
理由はReLU関数は x > 0 の部分では微分値が常に1であるため勾配消失の心配が無いためです。
なお、ReLU関数は出力層の活性化関数に用いられることはあまりありません。
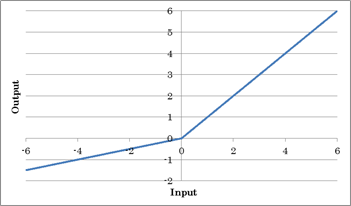
Leaky ReLU
ReLUはxが0以下の入力に対して常に0を出力するのに対し、LeakyReLUはxが0以下の入力に対しても一定値をかけて出力するようにしたものです。
数式
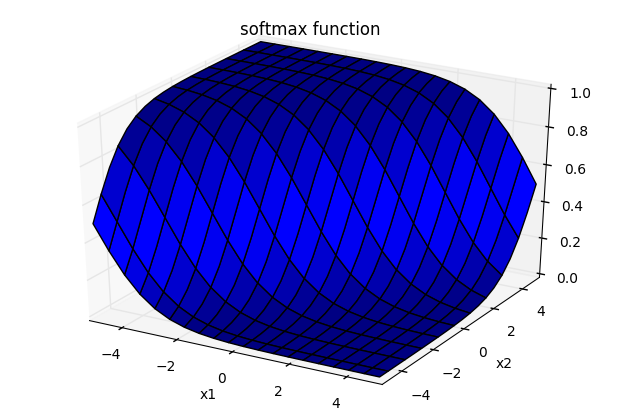
o=max(0, x) + a×min(0, x)
max(0, x)は0かxの大きい方をyとする意味で、 min(0, x)は0かxの小さい方をyとする意味です。
上記の式は以下の様に書き表すこともできます。
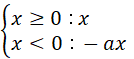
利用用途
LeakyReLU関数は中間層の活性化関数として現在最も多く用いられる関数の一つです。理由はLeakyReLU関数は微分値が常に1であるため勾配消失の心配が無いためです。ReLUに合ったxが0以下の場合に微分係数が常に0となり誤差が逆伝播しない問題をLeakyReLUは改善しており、現在最も多く用いられる関数の一つです。(※1)
※1 LeakyReLUの発案者がReLUの代わりにLeakyReLUを用いる意味はなかったと言っていますので、中間層の活性化関数にはReLUを使うでも良いかもしれません。
ソフトマックス関数(Softmax Function)
入力値のSoftmax値を出力します。カテゴリ分類問題における確率など、出力値が0.0~1.0の範囲かつ、出力値の合計が1.0となる出力値を得たい場合に使用します。
ソフトマックス関数を使うと例えばある画像が犬か猫である確率を算出したい場合に、y1=犬である確率, y2 = 猫である確率とし、y1 = 0.3、y2 = 0.7 の様に表すことができます。犬である確率が30%、猫である確率が70%で合計値は100%と表せ分かり易い分類が出来ます。
数式
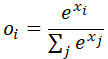
oは出力、xは入力、iはデータのIndexを示す。
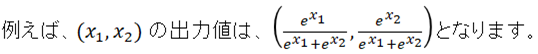
参考) Softmaxのグラフ
利用用途
Softmax関数は多値分類問題を解く場合に出力層で用いります。
ELU関数(Exponential Linear Unit)
ReLUはxが0以下の入力に対して常に0を出力するのに対し、ELUはxが0以下の入力に対しても一定値をかけて出力するようにしたものです。ELUと似たような関数にLeakyReLUがあります。LeakyReLUとELUの違いはx < 0以下の計算に指数関数を用いていることです。
数式
o=max(0, x) + alpha(exp(min(0, x)) – 1)
max(0, x)は0かxの大きい方をyとする意味で、 min(0, x)は0かxの小さい方をyとする意味です。
alphaは係数です。
上記の式は以下の様に書き表すこともできます。
利用用途
ELU関数は中間層の活性化関数として用いられる関数の一つです。理由はELU関数は微分値が常に1であるため勾配消失の心配が無いためです。ReLUに合ったxが0以下の場合に微分係数が常に0となり誤差が逆伝播しない問題をELUは改善しています。
出典: [https://www.procrasist.com/entry/2017/01/12/200000]
SELU関数(Scaled Exponential Linear Unit)
SELU 関数は、自己正規化特性を持つように設計されています。これは、ネットワークの各層の出力が、平均値 0、標準偏差 1 の正規分布になるようにスケールされます。この自己正規化により、勾配消失問題や勾配爆発問題を抑制し、深層ネットワークの学習を安定化することができます。SELUはELUに係数を掛けて算出します。
数式
o=lambda{max(0, i) + alpha(exp(min(0, i)) – 1)}
これは、
o=lambda(ELU(i)) と置き換えられます。つまりSELUはELUに係数lambdaを掛けたものです。
利用用途
自己正規化特性は、深層ネットワークの学習プロセスを安定化させるのに役立ちます。これは、深層ネットワークにおいては、初期の層での小さな変化が後の層に伝播されていくにつれて、変化が大きくなり、勾配消失や勾配爆発が発生しやすいためです。SELU は、各層の出力を正規化することで、この問題を解決することができます。
スウィッシュ関数(swish Function)
Googleが提案した活性化関数で、x * sigmoid(x)という形になります。SwishはReLUに似た形をもつ関数です。しかしReLUと違い、原点において連続であり単調関数ではありません。Swishは複数の論文において提案されており、ReLUの代わりになる活性化関数を探すために強化学習を用いた探索を行い、その結果としてSwishが一番良い性能を発揮しましたと発表されています。
数式
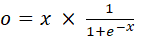
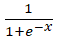 はシグモイド関数です。
はシグモイド関数です。
つまりSwishはo = x × sigmoid(x) です。

参考) シグモイド関数のグラフ

利用用途
Swish関数はReLUの代わりに中間層の活性化関数として用いることで、学習精度の向上する可能性があります。現在中間層で最も多く用いられる関数の一つです。
ソフトプラス関数(Softplus Function)
Softplus関数は、ReLU関数の滑らかな近似であり、学習の停滞を防ぎ、負の入力に関する情報を保持することができます。しかし、計算コストが高く、出力範囲が大きくなる可能性があるという欠点もあります。
Softplus関数は、ReLU関数と比較して、より複雑なモデルの学習や確率モデルの構築に適していると考えられます。
数式
softplus(x) = log(1 + exp(x))
利用用途
Softplus関数は、深層ニューラルネットワークにおいて、他の活性化関数と組み合わせて使用されることがあります。
Dense(全結合ニューラルネットワーク)を用いるディープラーニングのモデル
Dense(全結合ニューラルネットワーク)はディープラーニングの全モデルで用いられる、ディープラーニングの中核となるレイヤーです。全結合層と活性化関数の組み合わせが深いレイヤー構成になるのでディープラーニングと呼ばれる所以で、全結合層が無くしてディープラーニングはありません。
【ディープラーニングのネットワーク構成のイメージ】
kerasの活性化関数の指定方法
kerasではレイヤーのactivationパラメタに活性化関数を指定します。
model = keras.Sequential([
keras.layers.Dense(128, activation='relu', input_shape=(10,)), # 入力層
keras.layers.Dense(64, activation='relu'), # 中間層
keras.layers.Dense(10, activation='softmax') # 出力層
])ディープラーニングの実装サンプル(keras)
KerasのDenseレイヤーを用いたシンプルなニューラルネットワークの実装サンプルを示します。この例では、MNISTデータセット(手書き数字の画像データ)を使って、数字の画像を分類するためのモデルを構築します。
import numpy as np
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Flatten
from keras.utils import to_categorical
# MNISTデータセットの読み込み
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# データの前処理
x_train = x_train.astype('float32') / 255 # ピクセル値を0から1の範囲に正規化
x_test = x_test.astype('float32') / 255 # ピクセル値を0から1の範囲に正規化
# ラベルをカテゴリカルに変換
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# モデルの作成
model = Sequential()
# 入力層と最初の全結合層(Flattenを使用して2次元の画像データを1次元に変換)
model.add(Flatten(input_shape=(28, 28)))
model.add(Dense(units=128, activation='relu'))
# 隠れ層
model.add(Dense(units=64, activation='relu'))
# 出力層
model.add(Dense(units=10, activation='softmax'))
# モデルのコンパイル
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# モデルの訓練
model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
# モデルの評価
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f'Test accuracy: {test_acc:.4f}')このコードを実行すると、MNISTデータセットを使って手書き数字を分類するためのシンプルなニューラルネットワークモデルが構築され、訓練および評価されます。
Kerasリファレンス
Kerasの詳しい使い方は本家の以下ページを参照下さい。
https://keras.io/api/
最後に
本記事がAIの理解に少しでもお役に立てば幸いです。機械学習など分かり易く記事にしていきますので今後とも宜しくお願いします。

一緒に楽しくAIについて学びましょう。
|
|
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/3d0012c2.63b52d2d.3d0012c3.168768c3/?me_id=1285657&item_id=12143578&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbookfan%2Fcabinet%2F00877%2Fbk4627854811.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")
