誰でもわかる!生成AIの仕組みを徹底解説

初めに

こんにちは。イムでーす。今日はAIの生成機能について説明するねー。
この記事では、世界で話題の生成AIの仕組みについて、誰でも理解できるように詳しく解説します。特に、生成AIの心臓部と言える「生成機能」に焦点を当て、その仕組みと、プログラムでは実現できない生成AIならではの能力について詳しく説明します。
生成機能とは
生成とは何でしょうか?
それは何かを作り出すことです。絵を描く、音楽を作る、小説を書く、そして質問に答えること、これら全てが生成機能に含まれます。
生成はAIだけの特技?
AIの生成機能は、プログラムでは実現できない高度な能力です。従来のプログラムは、予め決められた手順に従って動作するため、新しいものを生み出すことは苦手でした。
例えば、チャットボットは、事前に用意された回答の中から適切なものを選択して返答する仕組みです。また、スクリーンセーバーのCGは、幾何学的なパターンをプログラムで描画しているに過ぎませんでした。

生成の仕組みを深掘り!
プログラムによる「もどき」生成
質疑応答
質問に対して、あらかじめ用意された回答の中からランダムに一つを選び、返答する仕組みです。
例えば、「おはよう」と入力された場合、プログラムは「ご機嫌よう」「おはよう、今日は良い天気ですね」「おはよう、今日はちょっと体調が優れません」といった選択肢の中から、ランダムに一つを選んで返答します。
画像の作成
プログラムで画像を作成する場合、事前に線の位置、色、点を指定する必要があります。しかし、この方法では、同じ絵しか生成できません。そこで、線の位置や色を、数式を用いてパラメータで変化させることで、異なる絵を生成することができます。
例えば、3DのCGでは、カメラの位置をパラメータとして設定することで、360度の画像を生成することが可能です。
音声の生成
朗読もプログラムで可能です。極端に言えば、「あ」「い」「う」に対応した音声録音しておいて、1文字1文字再生すればプログラムで朗読が出来ます。
プログラムによる朗読の方法は、こちらの記事で詳しく説明しているのでご参照下さい。
プログラムではできない生成
プログラムでは「もどき」生成しか実現できませんでした。では、真の生成、つまり新しいものを生み出す能力とはどの様な仕組みかを見ていくことにしましょう。
人間による創造
人間は、新しいものを生み出す一つの方法として、「模倣」と「評価」を繰り返しています。
例えば、習字を学ぶ場合、まずは見本の文字を真似て書きます。これが「模倣」です。そして、書いた文字がどれだけ見本に近いかを確認します。これが「評価」です。
しかし、このプロセスだけでは、見本と同じものしか作れません。では、人間はなぜ新しいものを生み出せるのでしょうか?
それは、人間が完璧な模倣ができないからです。人間は、完璧なコピーを作成しようとすると、必ずどこかでずれが生じます。そのずれこそが、新しいものを生み出す原動力となります。
習字の例で言えば、人間は完璧に見本と同じ文字を書くことはできません。必ずどこかで崩れたり、筆の運びが変わったりします。しかし、その崩れや変化によって、見本よりも良い文字が生まれることもあります。
人間は、完璧な模倣ができない一方で、完璧ではないものも受け入れ、評価することができます。この「不完全性」と「曖昧」な評価能力が、人間に新しいものを生み出す力を与えているのです。

AIによる創造
AIも、人間と同じ方法で新しいものを生み出します。AIは、プログラムとは異なり、完璧ではありません。むしろ、AIは意図的に「不完全性」と「曖昧性」を備えています。
AIは、完璧な模倣ができないため、見本とは少し異なる結果を生成します。しかし、その一方で、曖昧な評価を行う能力も持っています。そのため、見本と全く同じでなくても、良いものかどうかを判断することができます。
AIは、人間と同じように「模倣」と「評価」を繰り返すことで、見本とは異なる、しかしより良いものを生み出すことができるのです。

生成モデルGAN
生成AIを実現する代表的なモデルの一つに「GAN(Generative Adversarial Networks)」があります。GANは、日本語で「敵対的生成ネットワーク」と呼ばれ、2つのニューラルネットワーク(生成器と識別器)が互いに競い合うことで、データを生成する仕組みです。
-
生成器(Generator)
ランダムなノイズを入力として、本物と区別がつかないような偽物のデータを生成します。 -
識別器(Discriminator)
生成器が生成した偽物のデータと本物のデータを区別します。
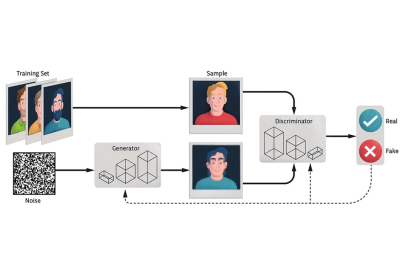
GANの実装例
ここでは、Kerasライブラリを用いて、手書き数字(MNIST)を生成するGANの実装例を紹介します。
必要なライブラリのインポート
from keras.datasets import mnist # MNISTデータセットをロードするためのライブラリ
from keras.layers import Input, Dense, Reshape, Flatten, Dropout # Kerasの層定義用ライブラリ
from keras.layers import BatchNormalization, Activation, ZeroPadding2D # バッチ正規化、活性化関数、パディング用の層
from keras.layers.advanced_activations import LeakyReLU # Leaky ReLU活性化関数
from keras.models import Sequential, Model # モデル定義用ライブラリ
from keras.optimizers import Adam # Adam最適化アルゴリズム
import matplotlib.pyplot as plt # グラフ描画用ライブラリ
import numpy as np # 配列操作用ライブラリ生成器の構築
def build_generator():
model = Sequential() # 順方向のモデルを定義
# 生成器の層を定義
model.add(Dense(256, input_dim=100)) # 入力層: ノイズベクトル(100次元)を受け取る
model.add(LeakyReLU(alpha=0.2)) # Leaky ReLU活性化関数
model.add(BatchNormalization(momentum=0.8)) # バッチ正規化層
model.add(Dense(512)) # 全結合層
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(28 * 28 * 1, activation='tanh')) # 出力層: 28x28ピクセルの画像(1チャンネル)を生成
model.add(Reshape((28, 28, 1))) # 画像の形状に再整形
# 入力層と出力層を指定してモデルを構築
noise = Input(shape=(100,)) # ノイズベクトルを入力
img = model(noise) # モデルにノイズを入力して画像を生成
return Model(noise, img) # モデルを返す識別器の構築
def build_discriminator():
model = Sequential() # 順方向のモデルを定義
# 識別器の層を定義
model.add(Flatten(input_shape=(28, 28, 1))) # 入力層: 28x28ピクセルの画像(1チャンネル)を受け取る
model.add(Dense(512)) # 全結合層
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid')) # 出力層: 本物か偽物かを判定(0: 偽物、1: 本物)
# 入力層と出力層を指定してモデルを構築
img = Input(shape=(28, 28, 1)) # 画像を入力
validity = model(img) # モデルに画像を入力して判定結果を生成
return Model(img, validity) # モデルを返すGANの結合
def build_gan(generator, discriminator):
discriminator.trainable = False # 識別器の学習を一時的に停止
z = Input(shape=(100,)) # ノイズベクトルを入力
img = generator(z) # 生成器にノイズを入力して画像を生成
validity = discriminator(img) # 識別器に生成された画像を入力して判定結果を生成
return Model(z, validity) # ノイズから判定結果までのモデルを返す訓練プロセスの定義
def train(epochs, batch_size=128, save_interval=50):
(X_train, _), (_, _) = mnist.load_data() # MNISTデータセットをロード
X_train = (X_train.astype(np.float32) - 127.5) / 127.5 # 画像データを-1から1の範囲に正規化
X_train = np.expand_dims(X_train, axis=3) # 画像データのチャンネル数を1に拡張
valid = np.ones((batch_size, 1)) # 本物の画像ラベル(1)を定義
fake = np.zeros((batch_size, 1)) # 偽物の画像ラベル(0)を定義
for epoch in range(epochs): # エポック数分繰り返し学習
idx = np.random.randint(0, X_train.shape[0], batch_size) # バッチサイズ分の画像データをランダムに選択
imgs = X_train[idx] # 選択した画像データを格納
noise = np.random.normal(0, 1, (batch_size, 100)) # ノイズを生成
gen_imgs = generator.predict(noise) # 生成器にノイズを入力して画像を生成
# 識別器の学習
d_loss_real = discriminator.train_on_batch(imgs, valid) # 識別器を本物の画像で学習
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake) # 識別器を偽物の画像で学習
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake) # 識別器の損失を計算
# 生成器の学習
noise = np.random.normal(0, 1, (batch_size, 100)) # ノイズを生成
g_loss = gan.train_on_batch(noise, valid) # 生成器を学習
print(f"{epoch} [D loss: {d_loss[0]}, acc.: {100*d_loss[1]}] [G loss: {g_loss}]") # 学習状況を出力
if epoch % save_interval == 0: # 一定間隔で画像を保存
save_imgs(epoch)生成画像の保存
def save_imgs(epoch):
r, c = 5, 5 # 画像の表示グリッドサイズ
noise = np.random.normal(0, 1, (r * c, 100)) # ノイズを生成
gen_imgs = generator.predict(noise) # 生成器にノイズを入力して画像を生成
gen_imgs = 0.5 * gen_imgs + 0.5 # 画像データを0から1の範囲に変換
fig, axs = plt.subplots(r, c) # 画像を表示するキャンバスを作成
cnt = 0
for i in range(r):
for j in range(c):
axs[i, j].imshow(gen_imgs[cnt, :, :, 0], cmap='gray') # 生成された画像を表示
axs[i, j].axis('off') # 軸を非表示
cnt += 1
fig.savefig(f"images/mnist_{epoch}.png") # 画像を保存
plt.close()実行
optimizer = Adam(0.0002, 0.5) # Adam最適化アルゴリズムを定義
discriminator = build_discriminator() # 識別器を構築
discriminator.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy']) # 識別器をコンパイル
generator = build_generator() # 生成器を構築
gan = build_gan(generator, discriminator) # GANを構築
gan.compile(loss='binary_crossentropy', optimizer=optimizer) # GANをコンパイル
train(epochs=30000, batch_size=64, save_interval=200) # 訓練を開始AI生成モデルの用途
生成AIは、画像、テキスト、音声、映像など、様々な分野で活用されています。
1. 画像生成
- アートとデザイン: 新しいアート作品の生成やデザインのアイディア出し
- ゲーム開発: ゲームキャラクターや背景の自動生成
2. テキスト生成
- コンテンツ作成: 記事、ブログ、ストーリーの自動生成、製品説明や広告文の生成
- 対話システム: チャットボットやカスタマーサポートシステムの構築
- 翻訳と要約: 自然言語処理を使った自動翻訳や文書要約
3. 音声生成
- 音楽作成: 曲やメロディの自動生成、特定のスタイルやジャンルの音楽の生成
- 音声合成: テキスト読み上げ(TTS)システム、有名人や特定のキャラクターの声を模倣
4. 映像生成
- ビデオ制作: 短編ビデオクリップやアニメーションの生成、特定のテーマやストーリーに基づく映像の生成
- 仮想現実(VR)と拡張現実(AR): 仮想空間やARコンテンツの生成
5. 創作活動の支援
- 文学とライティング: 詩や短編小説の自動生成、作家やライターのインスピレーションを得るためのアイディア提供
- ファッションとデザイン: 新しい服やアクセサリーのデザインアイデアの生成
生成AIの利用における注意点
生成AIは非常に便利ですが、利用する際には注意すべき点もいくつかあります。生成AIを利用する際は次の様なことを意識し利用者がチェックし適切に利用することが重要となります。
1. データ品質とバイアス
生成AIは、トレーニングデータの影響を大きく受けます。トレーニングデータが偏っていたり、不正確なデータを含んでいる場合、生成されたコンテンツも同様に偏ったり、不正確なものになる可能性があります。また、トレーニングデータに社会的、文化的、倫理的なバイアスが含まれている場合、それが生成結果に反映されることもあります。
そのため、生成AIの利用者は、生成されたコンテンツを鵜呑みにせず、別の方法で検証することが重要です。
2. プライバシーとセキュリティ
生成AIに個人情報を含むデータでトレーニングすると、生成されたコンテンツが個人情報を無意識に露出する可能性があります。そのため、生成AIに個人情報を与えないように注意する必要があります。
3. 著作権と知的財産
生成されたコンテンツが既存の著作物に似ている場合、著作権侵害の問題が発生する可能性があります。生成AIの利用者は、利用する生成AIが著作権を侵害する可能性があるかどうか、利用規約などを確認する必要があります。
本日のまとめ
- 生成AIは、プログラムでは実現できない「新しい発想」に基づいた「創造」を可能にする技術です。
- AIは、人間と同じように「模倣」と「評価」を繰り返すことで、見本とは異なる、しかしより良いものを生み出します。
- 生成AIを実現する代表的なモデルに「GAN」があります。
- 生成AIは、画像、テキスト、音声、映像など、様々な分野で活用されています。
- 生成AIを利用する際には、データ品質、プライバシー、著作権など、様々な点に注意する必要があります。
※より伝わり易い記事を目指し、本記事の内容はAIにより添削しております。